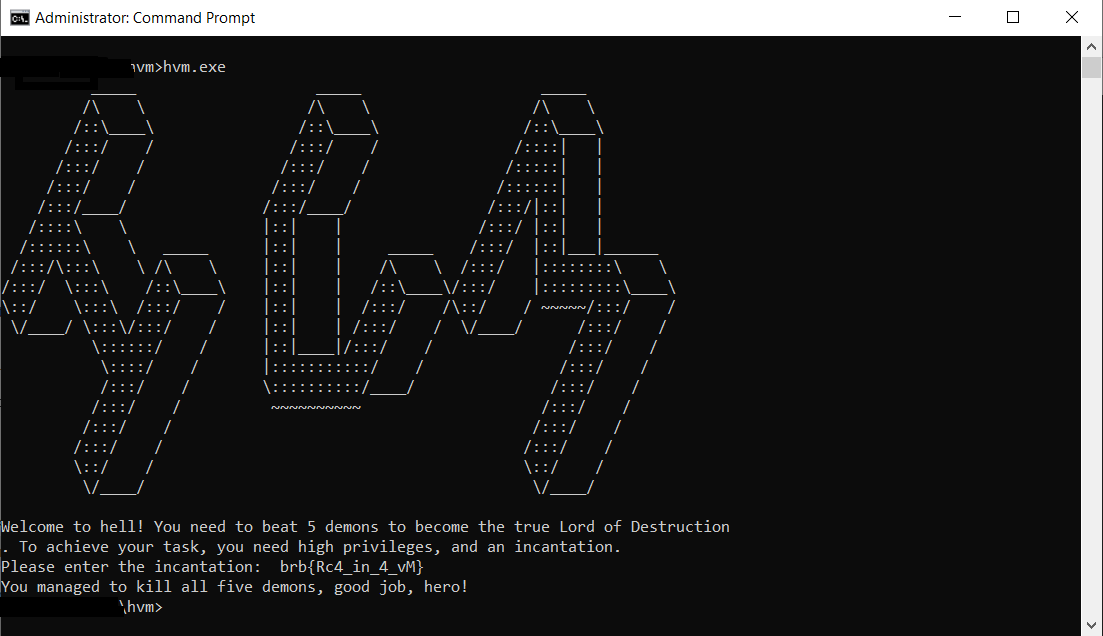
s4r's hvm solution
This is my old solution for s4r’s hvm crackme
Analyze the crackme
As the crackme’s description said that it’s a virtual machine (vm) one. Usually I will go quick while talking about reverse engineering the vm interpreter and will go into detail about vm ops code, what kind of vm, how does vm work,…. But this crackme worth to talk about the vm interpreter. The way crackme run the vm is very creative. It creates total 5 process with share vm memory. Each process will execute one vm instruction, then random pass the execution of next instruction to another process. By doing this crackme will make sure it run the vm code in 5 different process without changing the vm context. See image bellow

Also the vm decrypt the vm code and vm context each time it start executing vm instruction. After it finish executing instruction, it encrypt vm code and vm context again. The image below show how does crackme encrypt vm code and vm context after finishing execute vm instruction

The encryption is TEA with the keys is {0xCAFEBABE, 0xDEADBEEF, 0xABAD1DEA, 0xB19B00B5}. Keys can be found at the vm init
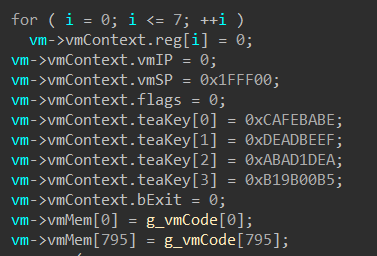
Here is the struct of the vm
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
struct SVMContext
{
int reg[7];
int vmSP;
int vmIP;
int flags;
DWORD teaKey[4];
int bExit;
};
struct SVM
{
DWORD vmMem[786432];
SVMContext vmContext;
};
Total size of vm struct is 0x301000. The details of vm struct are
- 0x0 – 0x2FFFFF: vm memory
- 0x0 – 0xFFFFF: vm code segment
- 0x100000 – 0x1FFFFF: vm stack segment
- 0x200000 – 0x2FFFFF: vm data segment
- 0x30000 – 0x30FFF: vm context
The vm ops code can be seen at the table below
| Ops code | Instruction |
|---|---|
| 2 | jump |
| 11 | je |
| 12 | add |
| 15 | exit |
| 17 | sub |
| 12 | mov |
| 23 | not |
| 24 | xor |
| 25 | shl |
| 26 | mod |
| 27 | and |
| 31 | or |
| 32 | call |
| 33 | ret |
| 34 | shr |
| 35 | cmp |
| 37 | get mem |
| 38 | pop |
| 42 | set mem |
| 54 | push |
| 57 | jne |
Here is a sample of add handler (code perform instruction add)
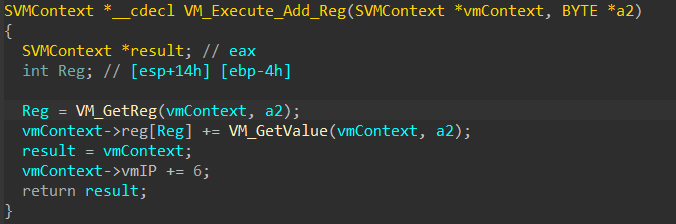
Analyze the VM
If the password length is 16, it will be copied to vm memory at offset 0x210000 then run the vm. To analyze the vm, we need to dump the vm memory (which include all necessary data such as password, vm data and vm code) then write a disassembler to analyze it. To dump the vm memory, just debugging it and dump the memory before it execute any vm instruction. You can find my dump here. There are many options to write a dissembler such as using C, python,… but in this case I wrote a small IDA processor to dissamble the vm code.
Click here to expand IDA Processor
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
from idc import *
from idautils import *
from idaapi import *
class hvm_processor_t(processor_t):
id = 0x8000 + 1212
flag = PR_ASSEMBLE | PRN_HEX
cnbits = 8
dnbits = 32
psnames = ["hvm"]
plnames = ["HVM Processor"]
segreg_size = 0
instruc_start = 0
assembler = {
"header": [".hvm"],
"flag": AS_NCHRE | ASH_HEXF0 | ASD_DECF0 | ASO_OCTF0 | ASB_BINF0,
"uflag": 0,
"name": "hvm assembler",
"origin": ".org",
"end": ".end",
"cmnt": ";",
"ascsep": "'",
"accsep": "'",
"esccodes": "\"'",
"a_ascii": ".ascii",
"a_byte": ".byte",
"a_word": ".word",
"a_dword": ".dword",
"a_bss": "dfs %s",
"a_seg": "seg",
"a_curip": "PC",
"a_public": "",
"a_weak": "",
"a_extrn": ".extern",
"a_comdef": "",
"a_align": ".align",
"lbrace": "(",
"rbrace": ")",
"a_mod": "%",
"a_band": "&",
"a_bor": "|",
"a_xor": "^",
"a_bnot": "~",
"a_shl": "<<",
"a_shr": ">>",
"a_sizeof_fmt": "size %s",
}
# size of a segment register in bytes
segreg_size = 0
reg_names = [
'r0',
'r1',
'r2',
'r3',
'r4',
'r5',
'r6',
'sp',
]
# Array of instructions
instruc = [
{'name': 'jmp', 'feature':CF_JUMP | CF_USE1, 'cmt': "Unconditional jump"},
{'name': 'je', 'feature':CF_JUMP | CF_USE1, 'cmt': "Jump if flag set to 1"},
{'name': 'add', 'feature':CF_USE1 | CF_USE2, 'cmt': "Add"},
{'name': 'exit', 'feature':CF_STOP, 'cmt': "Exit program"},
{'name': 'sub', 'feature':CF_USE1 | CF_USE2, 'cmt': "Sub"},
{'name': 'mov', 'feature':CF_USE1 | CF_USE2, 'cmt': "Mov"},
{'name': 'not', 'feature':CF_USE1, 'cmt': "Not"},
{'name': 'xor', 'feature':CF_USE1 | CF_USE2, 'cmt': "Xor"},
{'name': 'shl', 'feature':CF_USE1 | CF_USE2, 'cmt': "Shl"},
{'name': 'mod', 'feature':CF_USE1 | CF_USE2, 'cmt': "Mod"},
{'name': 'and', 'feature':CF_USE1 | CF_USE2, 'cmt': "And"},
{'name': 'or', 'feature':CF_USE1 | CF_USE2, 'cmt': "Or"},
{'name': 'call', 'feature':CF_CALL | CF_USE1, 'cmt': "Call"},
{'name': 'ret', 'feature':CF_STOP, 'cmt': "Ret"},
{'name': 'shr', 'feature':CF_USE1 | CF_USE2, 'cmt': "Shr"},
{'name': 'cmp', 'feature':CF_USE1 | CF_USE2, 'cmt': "Cmp"},
#{'name': 'mov', 'feature':0, 'cmt': "Get memory"},
{'name': 'pop', 'feature':CF_USE1, 'cmt': "Pop"},
#{'name': 'mov', 'feature':0, 'cmt': "Set memory"},
{'name': 'push', 'feature':CF_USE1, 'cmt': "Push register"},
{'name': 'jne', 'feature':CF_JUMP | CF_USE1, 'cmt': "Jump if flag set to 0"},
]
instruc_idx = {
'jmp' : 0,
'je' : 1,
'add' : 2,
'exit' : 3,
'sub' : 4,
'mov' : 5,
'not' : 6,
'xor' : 7,
'shl' : 8,
'mod' : 9,
'and' : 10,
'or' : 11,
'call' : 12,
'ret' : 13,
'shr' : 14,
'cmp' : 15,
'pop' : 16,
'push' : 17,
'jne' : 18,
}
# icode of the first instruction
instruc_start = 0
# icode of the last instruction + 1
instruc_end = len(instruc) + 1
# Segment register information (use virtual CS and DS registers if your
# processor doesn't have segment registers):
reg_first_sreg = 0 # index of CS
reg_last_sreg = 0 # index of DS
# You should define 2 virtual segment registers for CS and DS.
# number of CS/DS registers
reg_code_sreg = -1
reg_data_sreg = -1
def get_reg(self, op):
return (op >> 5) & 7
def get_value(self, ea, op_cmd):
if (get_wide_byte(ea + 1) & 1 != 0):
op_cmd.type = o_imm
op_cmd.value = get_wide_dword(ea + 2)
op_cmd.addr = get_wide_dword(ea + 2)
else:
op_cmd.type = o_reg
op_cmd.reg = (get_wide_byte(ea + 1) >> 2) & 7
return True
def get_mem(self, ea, op_cmd):
if (get_wide_byte(ea + 1) & 1 != 0):
op_cmd.type = o_phrase #address memory
op_cmd.value = get_wide_dword(ea + 2)
op_cmd.addr = get_wide_dword(ea + 2)
else:
op_cmd.type = o_displ #reg memory
op_cmd.reg = (get_wide_byte(ea + 1) >> 2) & 7
return True
def get_instruction_itype(self, name):
ret = self.instruc_idx.get(name)
if ret is not None:
return ret
else:
print("Could not find instruction %s" % name)
return -1
def get_instruction_name(self, itype):
for i, ins in enumerate(self.instruc):
if i == itype:
return ins['name']
def notify_func_bounds(self, code, func_ea, max_func_end_ea):
return FIND_FUNC_OK
def notify_out_operand(self, ctx, op):
if op.type == o_imm:
ctx.out_value(op, OOFW_32)
elif op.type == o_near:
ctx.out_name_expr(op, op.addr)
elif op.type == o_phrase:
ctx.out_symbol("[")
ctx.out_name_expr(op, op.addr)
ctx.out_symbol("]")
elif op.type == o_displ:
ctx.out_symbol("[")
ctx.out_register(self.reg_names[op.reg])
ctx.out_symbol("]")
elif op.type == o_reg:
ctx.out_register(self.reg_names[op.reg])
else:
return False
return True
def notify_out_insn(self, ctx):
ctx.out_line(self.get_instruction_name(ctx.insn.itype))
feature = ctx.insn.get_canon_feature()
ctx.out_spaces(5)
if feature & CF_USE1:
ctx.out_one_operand(0)
if feature & CF_USE2:
ctx.out_char(",")
ctx.out_char(" ")
ctx.out_one_operand(1)
ctx.flush_outbuf()
return
def notify_emu(self, cmd):
feature = cmd.get_canon_feature()
#Analyze instruction to make ref
if self.instruc[cmd.itype]['name'] in ('je', 'jne'):
if cmd[0].addr != 0 and cmd[0].type != o_reg:
add_cref(cmd.ea, cmd[0].addr, fl_JN)
flows = (feature & CF_STOP) == 0
if flows:
add_cref(cmd.ea, cmd.ea + cmd.size, fl_F)
elif self.instruc[cmd.itype]['name'] == 'call':
if cmd[0].addr != 0:
add_cref(cmd.ea, cmd[0].addr, fl_CN)
flows = (feature & CF_STOP) == 0
if flows:
add_cref(cmd.ea, cmd.ea + cmd.size, fl_F)
elif self.instruc[cmd.itype]['name'] == 'jmp':
if cmd[0].addr != 0 and cmd[0].type != o_reg:
add_cref(cmd.ea, cmd[0].addr, fl_JN)
else:
flows = (feature & CF_STOP) == 0
if flows:
add_cref(cmd.ea, cmd.ea + cmd.size, fl_F)
return True
def notify_ana(self, cmd):
optype = get_wide_byte(cmd.ea)
if optype == 2: #jump
cmd.itype = self.get_instruction_itype('jmp')
cmd.size = 6
self.get_value(cmd.ea, cmd[0])
if cmd[0].type == o_imm:
cmd[0].type = o_near
elif optype == 11: #je
cmd.itype = self.get_instruction_itype('je')
cmd.size = 6
self.get_value(cmd.ea, cmd[0])
if cmd[0].type == o_imm:
cmd[0].type = o_near
elif optype == 12: #Add register
cmd.itype = self.get_instruction_itype('add')
cmd.size = 6
cmd[0].type = o_reg
cmd[0].reg = self.get_reg(get_wide_byte(cmd.ea + 1))
self.get_value(cmd.ea, cmd[1])
elif optype == 15: #Exit
cmd.itype = self.get_instruction_itype('exit')
cmd.size = 6
elif optype == 17: #Sub
cmd.itype = self.get_instruction_itype('sub')
cmd.size = 6
cmd[0].type = o_reg
cmd[0].reg = self.get_reg(get_wide_byte(cmd.ea + 1))
self.get_value(cmd.ea, cmd[1])
elif optype == 22: #mov reg, value
cmd.itype = self.get_instruction_itype('mov')
cmd.size = 6
cmd[0].type = o_reg
cmd[0].reg = self.get_reg(get_wide_byte(cmd.ea + 1))
self.get_value(cmd.ea, cmd[1])
elif optype == 23: #not
cmd.itype = self.get_instruction_itype('not')
cmd.size = 6
cmd[0].type = o_reg
cmd[0].reg = self.get_reg(get_wide_byte(cmd.ea + 1))
self.get_value(cmd.ea, cmd[1])
elif optype == 24: #xor
cmd.itype = self.get_instruction_itype('xor')
cmd.size = 6
cmd[0].type = o_reg
cmd[0].reg = self.get_reg(get_wide_byte(cmd.ea + 1))
self.get_value(cmd.ea, cmd[1])
elif optype == 25: #shl
cmd.itype = self.get_instruction_itype('shl')
cmd.size = 6
cmd[0].type = o_reg
cmd[0].reg = self.get_reg(get_wide_byte(cmd.ea + 1))
self.get_value(cmd.ea, cmd[1])
elif optype == 26: #mod
cmd.itype = self.get_instruction_itype('mod')
cmd.size = 6
cmd[0].type = o_reg
cmd[0].reg = self.get_reg(get_wide_byte(cmd.ea + 1))
self.get_value(cmd.ea, cmd[1])
elif optype == 27: #and
cmd.itype = self.get_instruction_itype('and')
cmd.size = 6
cmd[0].type = o_reg
cmd[0].reg = self.get_reg(get_wide_byte(cmd.ea + 1))
self.get_value(cmd.ea, cmd[1])
elif optype == 31: #or
cmd.itype = self.get_instruction_itype('or')
cmd.size = 6
cmd[0].type = o_reg
cmd[0].reg = self.get_reg(get_wide_byte(cmd.ea + 1))
self.get_value(cmd.ea, cmd[1])
elif optype == 32: #call
cmd.itype = self.get_instruction_itype('call')
cmd.size = 6
self.get_value(cmd.ea, cmd[0])
if cmd[0].type == o_imm:
cmd[0].type = o_near
elif optype == 33: #ret
cmd.itype = self.get_instruction_itype('ret')
cmd.size = 6
elif optype == 34: #shr
cmd.itype = self.get_instruction_itype('shr')
cmd.size = 6
cmd[0].type = o_reg
cmd[0].reg = self.get_reg(get_wide_byte(cmd.ea + 1))
self.get_value(cmd.ea, cmd[1])
elif optype == 35: #cmp
cmd.itype = self.get_instruction_itype('cmp')
cmd.size = 6
cmd[0].type = o_reg
cmd[0].reg = self.get_reg(get_wide_byte(cmd.ea + 1))
self.get_value(cmd.ea, cmd[1])
elif optype == 37: #Get mem
cmd.itype = self.get_instruction_itype('mov')
cmd.size = 6
cmd[0].type = o_reg
cmd[0].reg = self.get_reg(get_wide_byte(cmd.ea + 1))
self.get_mem(cmd.ea, cmd[1])
elif optype == 38: #pop reg
cmd.itype = self.get_instruction_itype('pop')
cmd.size = 6
cmd[0].type = o_reg
cmd[0].reg = self.get_reg(get_wide_byte(cmd.ea + 1))
elif optype == 42: #set mem
#This is going to be weird to implement
cmd.itype = self.get_instruction_itype('mov')
cmd.size = 6
self.get_mem(cmd.ea, cmd[0])
cmd[1].type = o_reg
cmd[1].reg = self.get_reg(get_wide_byte(cmd.ea + 1))
#swap reg and value
cmd[0].reg, cmd[1].reg = cmd[1].reg, cmd[0].reg
cmd[0].value, cmd[1].value = cmd[1].value, cmd[0].value
cmd[0].addr, cmd[1].addr = cmd[1].addr, cmd[0].addr
elif optype == 54: #push
cmd.itype = self.get_instruction_itype('push')
cmd.size = 6
self.get_value(cmd.ea, cmd[0])
elif optype == 57: #jne
cmd.itype = self.get_instruction_itype('jne')
cmd.size = 6
self.get_value(cmd.ea, cmd[0])
if cmd[0].type == o_imm:
cmd[0].type = o_near
else:
print("Unknown instruction %X" % optype)
return cmd.size
def PROCESSOR_ENTRY():
return hvm_processor_t()
But wait, it doesn’t disasamble the code correctly.
That’s because the vm code is still encrypted by TEA. I wrote a small script to decrypt the vm code.
Click here to expand decrypting script
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
from idaapi import *
import base64
import ctypes
import itertools
import math
import struct
import hexdump
#TEA decryption was taken from https://gist.github.com/twheys/4e83567942172f8ba85058fae6bfeef5
def _chunks(iterable, n):
it = iter(iterable)
while True:
chunk = tuple(itertools.islice(it, n))
if not chunk:
return
yield chunk
def _str2vec(value, l=4):
n = len(value)
# Split the string into chunks
num_chunks = math.ceil(n / l)
chunks = [value[l * i:l * (i + 1)] for i in range(num_chunks)]
return [sum([character << 8 * j for j, character in enumerate(chunk)]) for chunk in chunks]
def _vec2str(vector, l=4):
#Modified to work
ret = b""
for e in vector:
ret += struct.pack("I", e)
return ret
def decrypt(ciphertext, key):
#Modified to work
if not ciphertext:
return ''
k = _str2vec(key[:16])
v = _str2vec(ciphertext)
return b''.join(_vec2str(_decipher(chunk, k)) for chunk in _chunks(v, 2))
def _decipher(v, k):
y, z = [ctypes.c_uint32(x)
for x in v]
sum = ctypes.c_uint32(0xC6EF3720)
delta = 0x9E3779B9
for n in range(32, 0, -1):
z.value -= (y.value << 4) + k[2] ^ y.value + sum.value ^ (y.value >> 5) + k[3]
y.value -= (z.value << 4) + k[0] ^ z.value + sum.value ^ (z.value >> 5) + k[1]
sum.value -= delta
return [y.value, z.value]
if __name__ == "__main__":
data = get_bytes(0, 0xC70)
key = struct.pack("IIII", 0xCAFEBABE, 0xDEADBEEF, 0xABAD1DEA, 0xB19B00B5)
decoded_data = decrypt(data, key)
hexdump.hexdump(decoded_data)
patch_bytes(0, decoded_data)
The result is very satisfying.
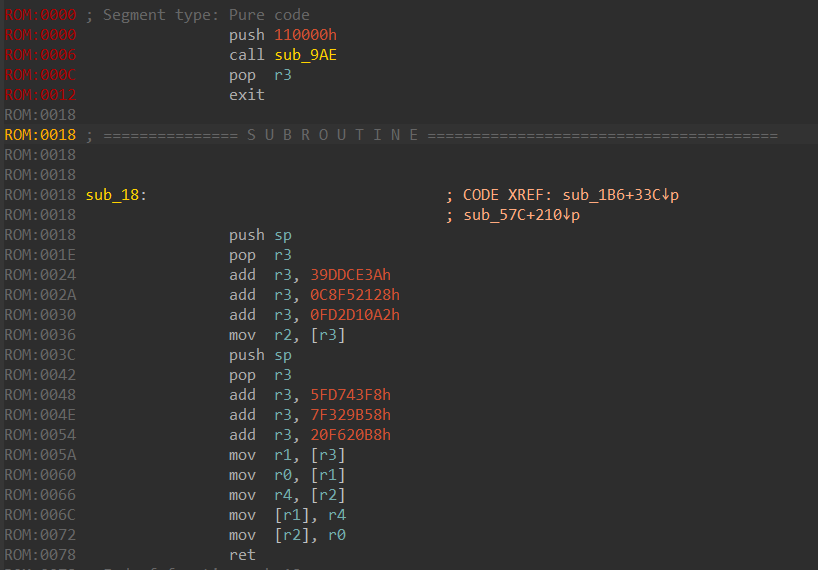
IDA even give us a beautiful graph
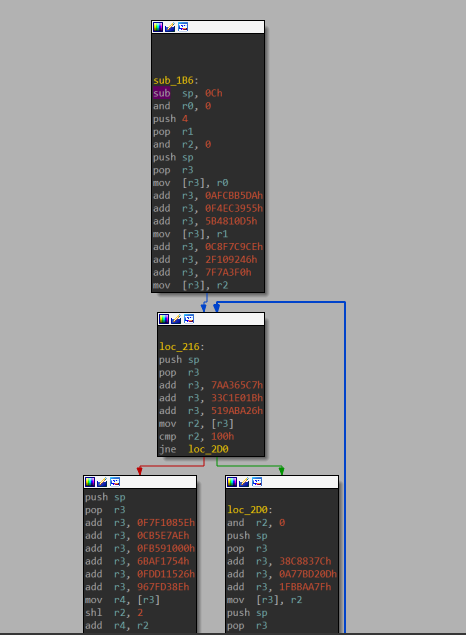
Almost done. There is still one thing: The obfuscation with add instruction as you can see in the image. I also wrote a small script to solve this little problem
Click here to expand helper script
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
from idc import *
from idautils import *
from idaapi import *
reg_names = [
'r0',
'r1',
'r2',
'r3',
'r4',
'r5',
'r6',
'sp',
]
def comment_add():
for func_ea in Functions(0, 0x0C66):
for (start_ea, end_ea) in Chunks(func_ea):
sum = 0
reg = -1
for head in Heads(start_ea, end_ea):
insn = DecodeInstruction(head)
if insn.itype == 2 and insn.Op1.type == o_reg and insn.Op2.type == o_imm:
if reg == -1:
reg = insn.Op1.reg
sum = (sum + insn.Op2.value) & 0xFFFFFFFF
else:
if insn.Op1.reg == reg:
sum = (sum + insn.Op2.value) & 0xFFFFFFFF
else:
sum = 0
reg = -1
else:
if reg != -1:
cmt_addr = idc.prev_head(head)
set_cmt(cmt_addr, "add %s, %Xh" % (reg_names[reg], sum), 0)
sum = 0
reg = -1
return
if __name__ == "__main__":
comment_add()
The script does the simple thing: Add the comment. The result is much more better

Now with the help of IDA, reverse engineering the vm become easier. Here is the rewritten of password checking algo (not exactly the same but at least it show how does the vm code run)
Click here to expand rewritten of password checking algo
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
#include <stdio.h>
#include <string.h>
const char plain1[] = "Who controls the past controls the future. Who controls the present controls the past.";
const char plain2[] = "We know that no one ever seizes power with the intention of relinquishing it.";
const char plain3[] = "Freedom is the freedom to say that two plus two make four. If that is granted, all else follows.";
const char plain4[] = "Perhaps one did not want to be loved so much as to be understood.";
const unsigned char enc1[] = {
0xAD, 0x44, 0x40, 0xC8, 0xDA, 0x68, 0xE2, 0x80, 0x64, 0xC4, 0x33, 0xA3, 0xEF, 0xA2, 0x8C, 0x51,
0x6A, 0x03, 0xFF, 0xDA, 0x7E, 0xC3, 0x18, 0x7B, 0x98, 0xCD, 0x75, 0x0D, 0x7A, 0xFB, 0x95, 0x25,
0x85, 0x7E, 0x7C, 0x5E, 0x71, 0xB2, 0xB7, 0xDE, 0x04, 0x59, 0xD8, 0xA9, 0x8D, 0xF8, 0x12, 0xBC,
0xB9, 0x8F, 0xB8, 0x41, 0xE6, 0x58, 0xB4, 0x05, 0x1D, 0xA9, 0xD7, 0x88, 0x43, 0xE7, 0xB6, 0x0C,
0xF1, 0x2B, 0x0B, 0x0E, 0x5C, 0x82, 0xC2, 0xAC, 0xF4, 0x2F, 0xC9, 0x5E, 0x9F, 0x9B, 0x83, 0xD7,
0x93, 0xCA, 0xB0, 0x89, 0x16, 0x8B
};
const unsigned char enc2[] = {
0x0A, 0xE5, 0xC7, 0x63, 0xE2, 0xB2, 0x1D, 0xB8, 0x9A, 0x03, 0x5D, 0xC5, 0xFC, 0xB1, 0x05, 0x6C,
0xA4, 0x7F, 0x02, 0x9C, 0xB0, 0xA7, 0x02, 0xAC, 0x6C, 0x50, 0x3A, 0x6D, 0xA2, 0xE0, 0x70, 0x38,
0x84, 0x61, 0xB4, 0xE3, 0x27, 0xE5, 0x56, 0xFC, 0x65, 0x9F, 0x28, 0x6C, 0x62, 0x3A, 0x70, 0xF8,
0x02, 0x73, 0x44, 0x2C, 0xDD, 0xC1, 0xA4, 0xB4, 0x9E, 0x24, 0x3B, 0xB9, 0xD5, 0xD4, 0xF0, 0x6D,
0xC0, 0x44, 0x22, 0x61, 0x8E, 0x66, 0x43, 0x62, 0x1E, 0x6C, 0x13, 0xAA, 0x87
};
const unsigned char enc3[] = {
0xAA, 0x84, 0xD7, 0x8F, 0xC8, 0xC2, 0xE3, 0x62, 0xC0, 0x9C, 0xFB, 0x64, 0x9E, 0x9E, 0xA3, 0x2A,
0x0B, 0xFB, 0x62, 0xC6, 0xC9, 0x66, 0x5C, 0xEC, 0xF5, 0x43, 0x3D, 0x16, 0x65, 0xA1, 0x80, 0xE0,
0x57, 0x99, 0x4C, 0xFE, 0x58, 0xF2, 0xA0, 0xC3, 0xC8, 0xCE, 0x1C, 0x2A, 0x63, 0x57, 0x59, 0xAE,
0xFC, 0xE3, 0x77, 0xB4, 0xAC, 0x9C, 0xA1, 0x17, 0xC5, 0x7B, 0x37, 0x9D, 0x94, 0x70, 0x40, 0x9B,
0x37, 0x52, 0x1D, 0xF1, 0xF5, 0xDB, 0xB2, 0x57, 0x82, 0xAB, 0xC8, 0x21, 0x38, 0xA8, 0x24, 0x73,
0x9A, 0xF4, 0xC5, 0x13, 0xF7, 0xF3, 0xAA, 0x32, 0xCC, 0xD1, 0xB2, 0x00, 0xE1, 0xF4, 0x5D, 0xC5
};
const unsigned char enc4[] = {
0x28, 0x52, 0x7F, 0x52, 0xB3, 0xE9, 0xF1, 0x12, 0xBC, 0x11, 0x41, 0xF9, 0x0A, 0xC5, 0x94, 0x70,
0x6E, 0x3C, 0x0D, 0x4E, 0xE3, 0xCB, 0x57, 0x8C, 0x35, 0x8E, 0xF6, 0x21, 0x4D, 0x6C, 0x7A, 0x01,
0x17, 0xC6, 0x93, 0x89, 0x54, 0x5A, 0x2E, 0xE0, 0xE8, 0x23, 0xE4, 0x12, 0x8E, 0xAF, 0x50, 0x89,
0xC9, 0xD7, 0x4B, 0x87, 0xE5, 0xEC, 0x78, 0x0E, 0xD5, 0xBC, 0x05, 0x30, 0xDB, 0x0D, 0x0C, 0x4A,
0xA6
};
const char* plain_array[] = { plain1, plain2, plain3, plain4 };
const unsigned char* enc_array[] = { enc1, enc2, enc3, enc4 };
const size_t size_array[] = { sizeof(plain1) - 1, sizeof(plain2) - 1, sizeof(plain3) - 1, sizeof(plain4) - 1 };
int rc4(const void* inbuf, void* outbuf, size_t buflen, const char* key, size_t keylen);
bool check_password(char* password)
{
int result = false;
unsigned char tmp[255];
for (int i = 0; i < 4; i++)
{
rc4(plain_array[i], tmp, size_array[i], &password[i * 4], 4);
result |= (memcmp(enc_array[i], tmp, size_array[i]) != 0)
}
return (result == false)
}
int main()
{
char password[16];
if (check_password(password))
printf("correct");
else
printf("wrong");
}
Sar did a good job. He implemented whole rc4 algo in vm code. Here is a few tips to know it’s rc4:
- There is a loop to fill an array with value from 0 to 255
- There is code does swap to variables
Getting the correct password
Now we know the vm algo. Here is the C++ code to brute force password
Click here to expand solution program
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
#include <stdio.h>
#include <string.h>
const char plain1[] = "Who controls the past controls the future. Who controls the present controls the past.";
const char plain2[] = "We know that no one ever seizes power with the intention of relinquishing it.";
const char plain3[] = "Freedom is the freedom to say that two plus two make four. If that is granted, all else follows.";
const char plain4[] = "Perhaps one did not want to be loved so much as to be understood.";
const unsigned char enc1[] = {
0xAD, 0x44, 0x40, 0xC8, 0xDA, 0x68, 0xE2, 0x80, 0x64, 0xC4, 0x33, 0xA3, 0xEF, 0xA2, 0x8C, 0x51,
0x6A, 0x03, 0xFF, 0xDA, 0x7E, 0xC3, 0x18, 0x7B, 0x98, 0xCD, 0x75, 0x0D, 0x7A, 0xFB, 0x95, 0x25,
0x85, 0x7E, 0x7C, 0x5E, 0x71, 0xB2, 0xB7, 0xDE, 0x04, 0x59, 0xD8, 0xA9, 0x8D, 0xF8, 0x12, 0xBC,
0xB9, 0x8F, 0xB8, 0x41, 0xE6, 0x58, 0xB4, 0x05, 0x1D, 0xA9, 0xD7, 0x88, 0x43, 0xE7, 0xB6, 0x0C,
0xF1, 0x2B, 0x0B, 0x0E, 0x5C, 0x82, 0xC2, 0xAC, 0xF4, 0x2F, 0xC9, 0x5E, 0x9F, 0x9B, 0x83, 0xD7,
0x93, 0xCA, 0xB0, 0x89, 0x16, 0x8B
};
const unsigned char enc2[] = {
0x0A, 0xE5, 0xC7, 0x63, 0xE2, 0xB2, 0x1D, 0xB8, 0x9A, 0x03, 0x5D, 0xC5, 0xFC, 0xB1, 0x05, 0x6C,
0xA4, 0x7F, 0x02, 0x9C, 0xB0, 0xA7, 0x02, 0xAC, 0x6C, 0x50, 0x3A, 0x6D, 0xA2, 0xE0, 0x70, 0x38,
0x84, 0x61, 0xB4, 0xE3, 0x27, 0xE5, 0x56, 0xFC, 0x65, 0x9F, 0x28, 0x6C, 0x62, 0x3A, 0x70, 0xF8,
0x02, 0x73, 0x44, 0x2C, 0xDD, 0xC1, 0xA4, 0xB4, 0x9E, 0x24, 0x3B, 0xB9, 0xD5, 0xD4, 0xF0, 0x6D,
0xC0, 0x44, 0x22, 0x61, 0x8E, 0x66, 0x43, 0x62, 0x1E, 0x6C, 0x13, 0xAA, 0x87
};
const unsigned char enc3[] = {
0xAA, 0x84, 0xD7, 0x8F, 0xC8, 0xC2, 0xE3, 0x62, 0xC0, 0x9C, 0xFB, 0x64, 0x9E, 0x9E, 0xA3, 0x2A,
0x0B, 0xFB, 0x62, 0xC6, 0xC9, 0x66, 0x5C, 0xEC, 0xF5, 0x43, 0x3D, 0x16, 0x65, 0xA1, 0x80, 0xE0,
0x57, 0x99, 0x4C, 0xFE, 0x58, 0xF2, 0xA0, 0xC3, 0xC8, 0xCE, 0x1C, 0x2A, 0x63, 0x57, 0x59, 0xAE,
0xFC, 0xE3, 0x77, 0xB4, 0xAC, 0x9C, 0xA1, 0x17, 0xC5, 0x7B, 0x37, 0x9D, 0x94, 0x70, 0x40, 0x9B,
0x37, 0x52, 0x1D, 0xF1, 0xF5, 0xDB, 0xB2, 0x57, 0x82, 0xAB, 0xC8, 0x21, 0x38, 0xA8, 0x24, 0x73,
0x9A, 0xF4, 0xC5, 0x13, 0xF7, 0xF3, 0xAA, 0x32, 0xCC, 0xD1, 0xB2, 0x00, 0xE1, 0xF4, 0x5D, 0xC5
};
const unsigned char enc4[] = {
0x28, 0x52, 0x7F, 0x52, 0xB3, 0xE9, 0xF1, 0x12, 0xBC, 0x11, 0x41, 0xF9, 0x0A, 0xC5, 0x94, 0x70,
0x6E, 0x3C, 0x0D, 0x4E, 0xE3, 0xCB, 0x57, 0x8C, 0x35, 0x8E, 0xF6, 0x21, 0x4D, 0x6C, 0x7A, 0x01,
0x17, 0xC6, 0x93, 0x89, 0x54, 0x5A, 0x2E, 0xE0, 0xE8, 0x23, 0xE4, 0x12, 0x8E, 0xAF, 0x50, 0x89,
0xC9, 0xD7, 0x4B, 0x87, 0xE5, 0xEC, 0x78, 0x0E, 0xD5, 0xBC, 0x05, 0x30, 0xDB, 0x0D, 0x0C, 0x4A,
0xA6
};
const char* plain_array[] = { plain1, plain2, plain3, plain4 };
const unsigned char* enc_array[] = { enc1, enc2, enc3, enc4 };
const size_t size_array[] = { sizeof(plain1) - 1, sizeof(plain2) - 1, sizeof(plain3) - 1, sizeof(plain4) - 1 };
int rc4_x86(const void* inbuf, void* outbuf, size_t buflen, const char* key, size_t keylen);
//brb{Rc4_in_4_vM}
int main()
{
char key[4];
char password[] = "????????????????";
unsigned char tmp[200];
int found_cnt = 0;
for (int char1 = 0x20; char1 <= 0x7E; char1++)
{
key[0] = char1;
for (int char2 = 0x20; char2 <= 0x7E; char2++)
{
key[1] = char2;
for (int char3 = 0x20; char3 <= 0x7E; char3++)
{
key[2] = char3;
for (int char4 = 0x20; char4 <= 0x7E; char4++)
{
key[3] = char4;
for (int i = 0; i < 4; i++)
{
rc4_x86(plain_array[i], tmp, size_array[i], key, 4);
if (memcmp(enc_array[i], tmp, size_array[i]) == 0)
{
*(unsigned int*)&password[i * 4] = *(unsigned int*)key;
found_cnt++;
printf("%s\n", password);
if (found_cnt == 4)
goto exit;
}
}
}
}
}
}
if (found_cnt != 4)
printf("Nothing found :(\n");
exit:
return 0;
}
int rc4_x86(const void* inbuf, void* outbuf, size_t buflen, const char* key, size_t keylen)
{
char s[256];
char* s_ptr = s;
char k[256];
char* k_ptr = k;
if (buflen <= 0)
return -1;
__asm {
mov eax, s_ptr
mov ecx, 256
fill_s:
xor ebx, ebx
sub bl, cl
mov[eax + ebx], bl
loop fill_s
}
// Generate k
__asm {
mov edx, key
mov edi, keylen;//edi = size of key
mov esi, k_ptr;//esi= k;
mov ecx, 256
xor ebx, ebx;//ebx=j
loop_j:
cmp ebx, edi
jl continue_loop
xor ebx, ebx;// clear ebx, move to the start of key, repeat until k is full
continue_loop:
mov ah, [edx + ebx]
mov[esi], ah
inc esi
inc ebx
loop loop_j
}
// Generate s
__asm {
mov edi, s_ptr
xor ebx, ebx
sub esi, 256
xor eax, eax
mov ecx, 256
loop_s:
mov dl, [esi + eax]
add bl, dl
mov dl, [edi + eax]
add bl, dl
mov dl, [edi + eax]
mov dh, [edi + ebx]
mov[edi + eax], dh
mov[edi + ebx], dl
inc eax
loop loop_s
}
__asm {
mov esi, inbuf;// esi = inbuf
mov edi, s_ptr;// edi = s
mov edx, outbuf;// edx = outbuf
;// clear registers
xor eax, eax
xor ebx, ebx
mov ecx, buflen;//ecx = buflen
cd:
push ecx
movzx ecx, al
inc cl
push edx
mov dh, [edi + ecx]
add bl, dh
mov dl, [edi + ebx]
mov[edi + ecx], dl
mov[edi + ebx], dh
add dl, dh
movzx edx, dl
mov dl, [edi + edx]
mov cl, [esi + eax]
xor cl, dl
pop edx
mov[edx + eax], cl
inc eax
pop ecx
loop cd
}
return buflen;
}
To compile it, you need visual studio (I’m a guy using Windows. Don’t blame me). After about 10 minutes, the brute force code give me the correct password is brb{Rc4_in_4_vM}